A Couple of Processes
When programmers write single-threaded, single-process programs, they can almost always answer the question “Do you know where your program is?” These types of programs are rather simple, looking something like
Figure 193.
If you use any debugger on these types of programs, you can almost always figure out what’s going on. Before the program begins executing, you set a
breakpoint, let the program run until it hits the breakpoint, and then inspect variables to see their values. If you suspect that there’s a logic problem, you can step the program through its statements to see where things are going wrong.
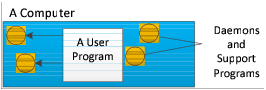
What is actually occurring, however, is a lot more complicated, since other programs are always executing on your computer. For example, your computing environment could have daemons and other support programs executing, and your program can interact with them.
These additional processes can simplify your program because it can hand off some tasks and not have to focus on how that work gets done.
Figure 194 shows a very simple architecture in which the application program just sends requests to a daemon.
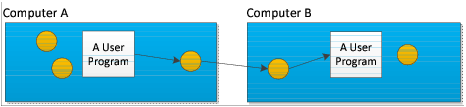
The type of architecture shown in
Figure 195 is more typical. In this example, an email program communicates with a daemon on one computer. After receiving a request, this daemon sends data to an email daemon on another computer, which then delivers the data to another mail program.
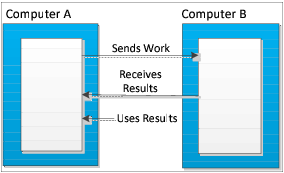
This architecture has one program handing off work to another. After the handoff, the programs do not interact. The program handing off the work just assumes that the work gets done. Some programs can work well like this. Most don’t. Most computational jobs do better with a model that allows a program to divide its work into smaller jobs, and parcel this work to other computers. Said in a different way, this model has other machines do some of the first program’s work. To gain any advantage, however, the work a program parcels out must be work that it doesn’t need right away. In this model, the two computers act more or less independently. And, because the first computer doesn’t have to do all the work, the program can complete its work faster.
Using more than one computer doesn’t mean that less computer time is being used. Overhead due to sending data across the network and overhead for coordinating multi-processing always means more work is being done. It does mean, however, that your program finishes sooner than if only one computer were working on the problem.
The TotalView Server Solution to Debugging Across Computers
One problem with this model is how a programmer debugs behavior on the second computer. One solution is to have a debugger running on each computer. The TotalView solution to this debugging problem places a server on each remote processor as it is launched. These servers then communicate with the main TotalView process. This debugging architecture gives you one central location from which you can manage and examine all aspects of your program.
NOTE >> TotalView can also attach to programs already running on other computers. In other words, programs don’t have to be started from within TotalView to be debugged by TotalView.
In all cases, it is far easier to initially write your program so that it only uses one computer. After it is working, you can split up its work so that it uses other computers. It is likely that any problems you find will occur in the code that splits the program or in the way the programs manipulate shared data, or in some other area related to the use of more than one thread or process.
NOTE >> Initially designing a multi-process application as a single-process program may not always be practical. For instance, some algorithms may take weeks to execute a program on one computer.